基于Grafana的可视化监控搭建
Prometheus
简介
Prometheus,翻译成中文叫普罗米修斯,是一个开源的系统监控和告警工具包,在许多企业和组织中都非常流行。Prometheus可以对需要监控的目标进行相关指标数据的采集,并以时间序列的方式保存到时序数据库中,还可以给数据打上标签(Label)一起存储。
Prometheus具有如下特点:
- 具有由指标名称和多维度键值对标签标识的时间序列数据的数据模型。
- 支持PromQL,一种灵活的查询语言。
- 不依赖分布式存储;单个服务器节点是自治的。
- 时间序列数据的收集通过HTTP上的拉模型进行。
- 支持通过中间网关推送时间序列数据。
- 支持通过服务发现或静态配置发现目标。
这是Prometheus的架构图:
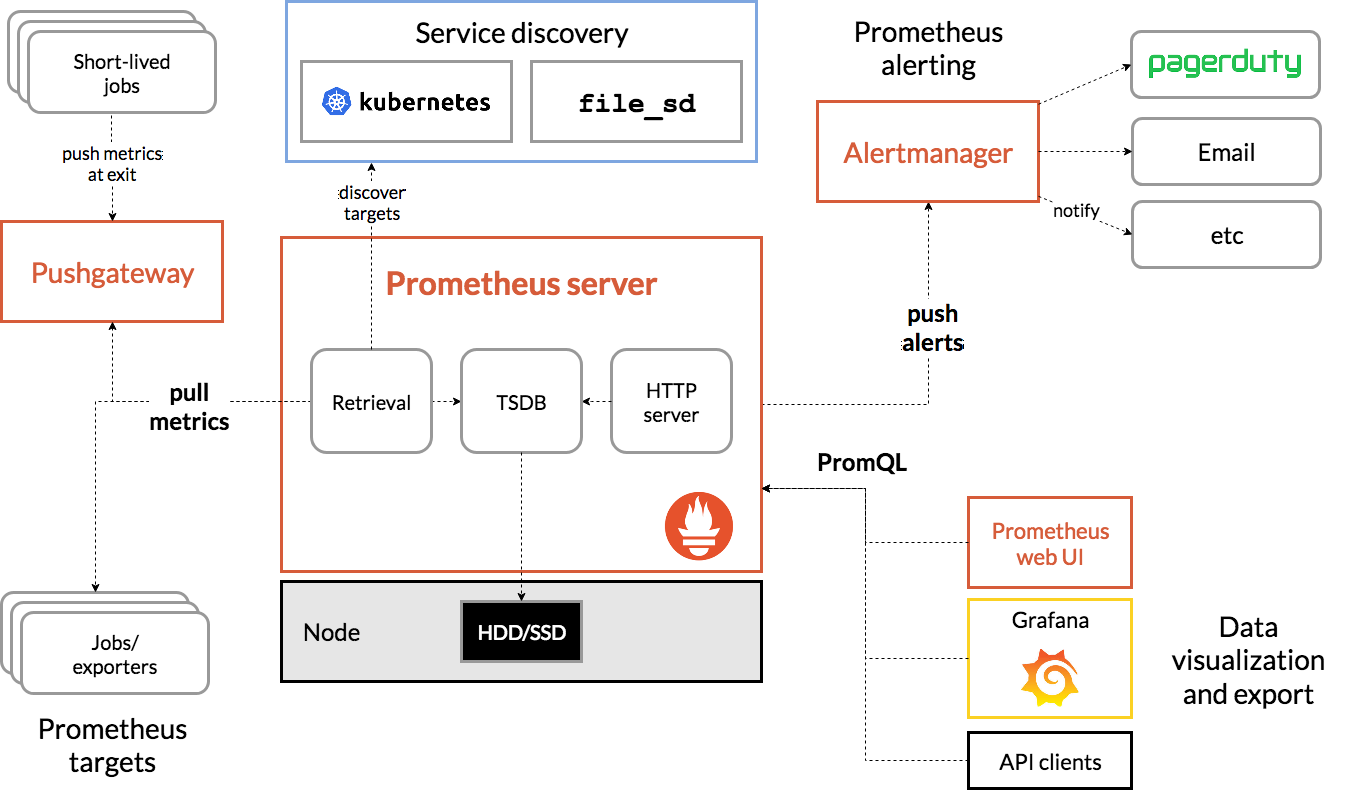
Prometheus是一个开源的完整监控解决方案,其对传统监控系统的测试和告警模型进行了彻底的改进,形成了基于中央化的规则计算、统一分析和告警的新模型。 相比于传统监控系统Prometheus具有以下优点:
易于部署和管理:Prometheus核心部分只有一个单独的二进制文件,不存在任何的第三方依赖(数据库,缓存等等)。唯一需要的就是本地磁盘,因此不会有潜在级联故障的风险。
工作模式清晰灵活:Prometheus基于Pull模型的架构方式,可以在任何地方(本地机器,开发环境,测试环境)上搭建监控系统。对于一些复杂的情况,还可以使用Prometheus服务发现(Service Discovery)的能力动态管理监控目标。
强大的数据模型:Prometheus可以很好地记录任何纯数字时间序列,所有采集到的监控数据均以指标和标签进行区分并保存在内置的时间序列数据库(TSDB)当中。一组时间序列数据除了基本的指标名称以外,还包含一组用于描述该时间序列数据特征的标签。
Prometheus比较适合:
以机器为中心的监控,也适合监控高度动态的面向服务的架构。在微服务的世界中,它对多维数据收集和查询的支持是一个特别的优势。
不适合:
Prometheus重视可靠性。用户始终可以查看有关系统的可用统计信息,即使在出现故障的情况下也是如此。因此如果用户需要百分之百的准确性,例如云厂商按请求计费,Prometheus不是一个好的选择,因为它收集的数据可能不够详细和完整。
metric
指标(metric),表示一种数字测量(numeric measurements),一个用户想要观测的数据。对于一个Web服务器来说,接口请求时间是一个指标,对于数据库来说,活动连接数是一个指标。
这些指标的数据随着时间的推移而变化,具有同一指标名称和标签的数据形成一组时间序列,Prometheus就记录这种变化,监控的目的就是分析这些变化所反映出来的信息。
exporter
exporter,可以翻译成导出器或者出口商,是受监控的目标暴露相关指标数据的地方。前面提到过,Prometheus是通过HTTP去拉取数据,也就是说受监控目标要提供一个HTTP接口供Prometheus访问。
这个HTTP接口不是可以返回任意数据模型给Prometheus的,要符合Prometheus的数据模型规范。
接口的端点一般是/metrics,接口可以由受监控目标系统自己通过引入Prometheus的客户端库实现,也可以通过第三方库将系统现有的一些指标数据转换成Prometheus指标数据,这对于无法直接提供 Prometheus指标数据(例如,HAProxy或Linux系统统计信息)的情况很有用。
这些提供Prometheus指标数据的HTTP接口,以及第三方库就被称为exporter。
下面的链接列出了一些官方和第三方提供的exporter:
Docker运行Prometheus
Prometheus支持多种安装方式,二进制的安装方式是直接去官网下载二进制包,解压后运行可执行文件就好了。这里介绍一种比较方便的安装方法,在Linux系统上,用Docker运行Prometheus。
创建docker-compoes.yml文件:
1 | version: '3' |
在/monitor/prometheus目录下创建prometheus.yml文件,这是Prometheus的配置文件:
1 | global: |
可以看到,Prometheus默认就配置了一个job,也就是监控任务,监控目标是Prometheus本身,Prometheus自己暴露了一个HTTP接口在9090端口供自己采集指标数据。
启动容器:
1 | $ docker-compose -d up |
通过curl访问exporter,可以看到返回的当前时间戳关于Prometheus自身的一些指标数据:
1 | [root@master ~]# curl localhost:9090/metrics |
Prometheus的数据模型就是这样:<metric name>{<label name>=<label value>, ...} value}。
在浏览器中输入http://ip:9090可以访问Prometheus的可视化界面:

可以看到Prometheus本身就是受监控目标。
Grafana
简介
Grafana是一个监控仪表系统,它是由Grafana Labs公司开源的的一个系统监测(System Monitoring)工具。Grafana可以大大地简化监控的复杂度,用户只需要提供监控得到的数据,Grafana就可以帮助用户生成各种各样的可视化仪表。同时Grafana还具有告警功能,可以在系统出现问题时通知用户。
数据源
Grafana本身不负责监控、采集数据,它只是提供一个通用的接口,让底层的数据库将数据传送给它(比如Prometheus),然后它再通过一系列仪表盘将数据可视化地展示出来。
Grafana的数据源不仅仅支持Prometheus这样的时序数据库,还支持关系数据库,比如MySQL,以及NoSQL,比如ElasticSearch。
Dashboard
目前较新版本的Grafana,是通过Dasboard(仪表盘)和Panel(仪表、面板)来组织和展示数据的。
一般来说,一个受监控系统的各项指标由一个Dashboard来进行展示,在Dashboard中,一个Panel展示一项指标。
用户可以手动一个个Panel进行配置,最终形成一个Dashboard。也可以在Grafana的社区中寻找合适的Dashboard模板,然后直接引入使用。
要想熟练配置Panel的话,需要对各种数据源的查询语言有所了解。
Docker运行Grafana
docker-compose.yml文件中进行配置:
1 | version: '3' |
通过命令运行:
1 | $ docker-compose -d up grafana |
运行成功后可以在浏览器中输入http://ip:3000进行访问Grafana,默认的初始账号密码均为admin,登录成功之后会让重设密码。
主机性能监控搭建
比较常见的监控,就是对服务器节点进行监控,以便可以实时地查看机器上的CPU、内存、硬盘以及网络流量等信息。
安装exporter
Linux系统信息很多都是以文件的方式进行查看的,比如查看内存信息:cat /proc/meminfo,所以需要一个exporter来对这些信息进行采集并转换成Prometheus指标数据,Prometheus官方专门提供了一个exporter来采集并暴露类Uninx系统的硬件和操作系统相关指标:
在Release页面下载相应架构的压缩包,上传到服务器后解压运行:
1 | $ tar -zxvf node_exporter-1.5.0.linux-amd64.tar.gz |
让exporter以后台进程的方式运行,打印出来的日志可以在同目录下的nohup.out文件中进行查看。通过下列命令查看exporter是否正常工作:
1 | $ curl localhost:9100/metrics |
如果正常,就会像上面的Prometheus自身相关的指标数据一样,返回操作系统和硬件相关的指标数据。
修改Prometheus配置
修改Prometheus配置文件,添加job:
1 |
|
重新启动Prometheus容器:
1 | $ docker-compose restart prometheus |
Grafana配置
添加Prometheus数据源
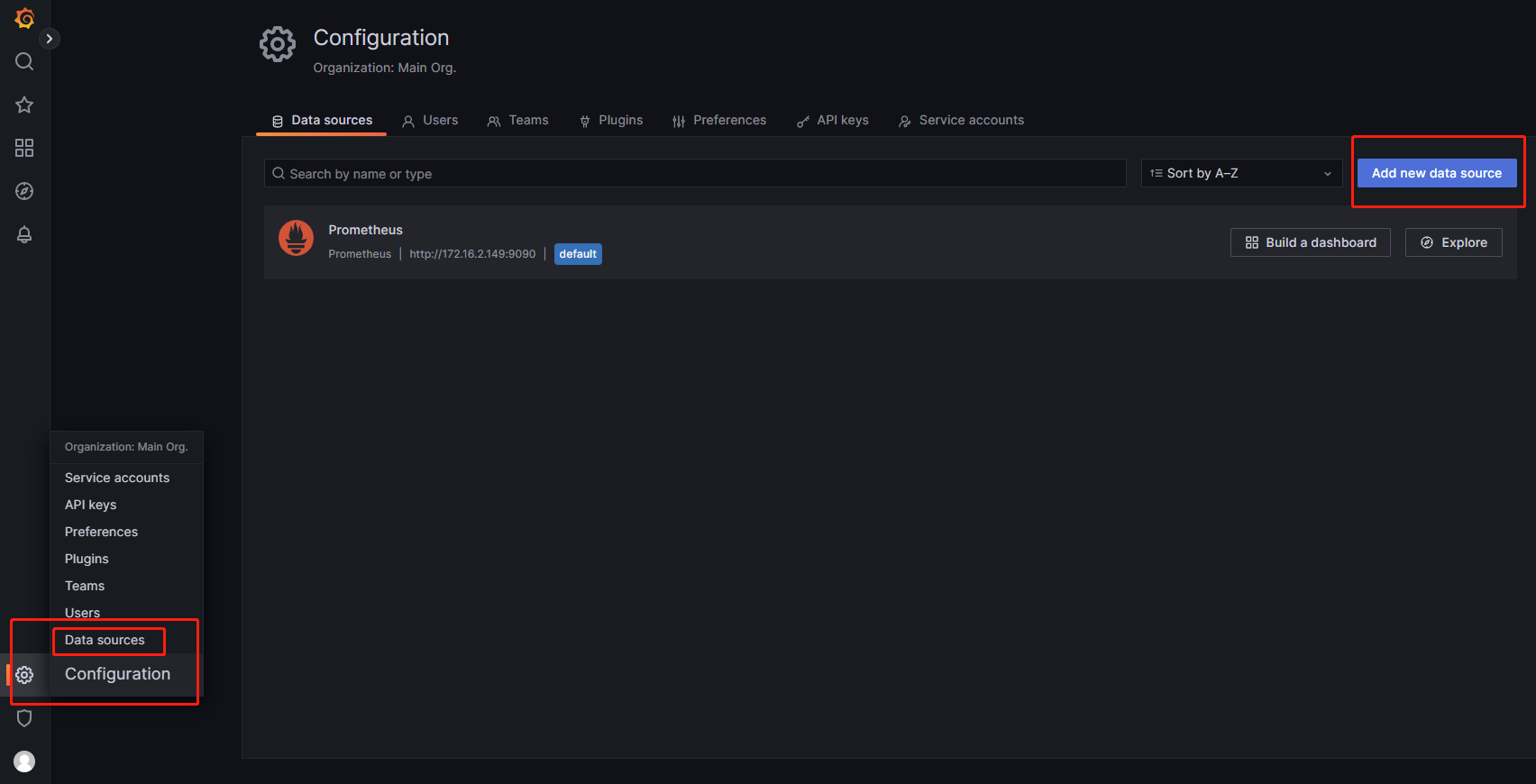
以admin身份登录Grafana,点击设置->数据源->添加数据源:
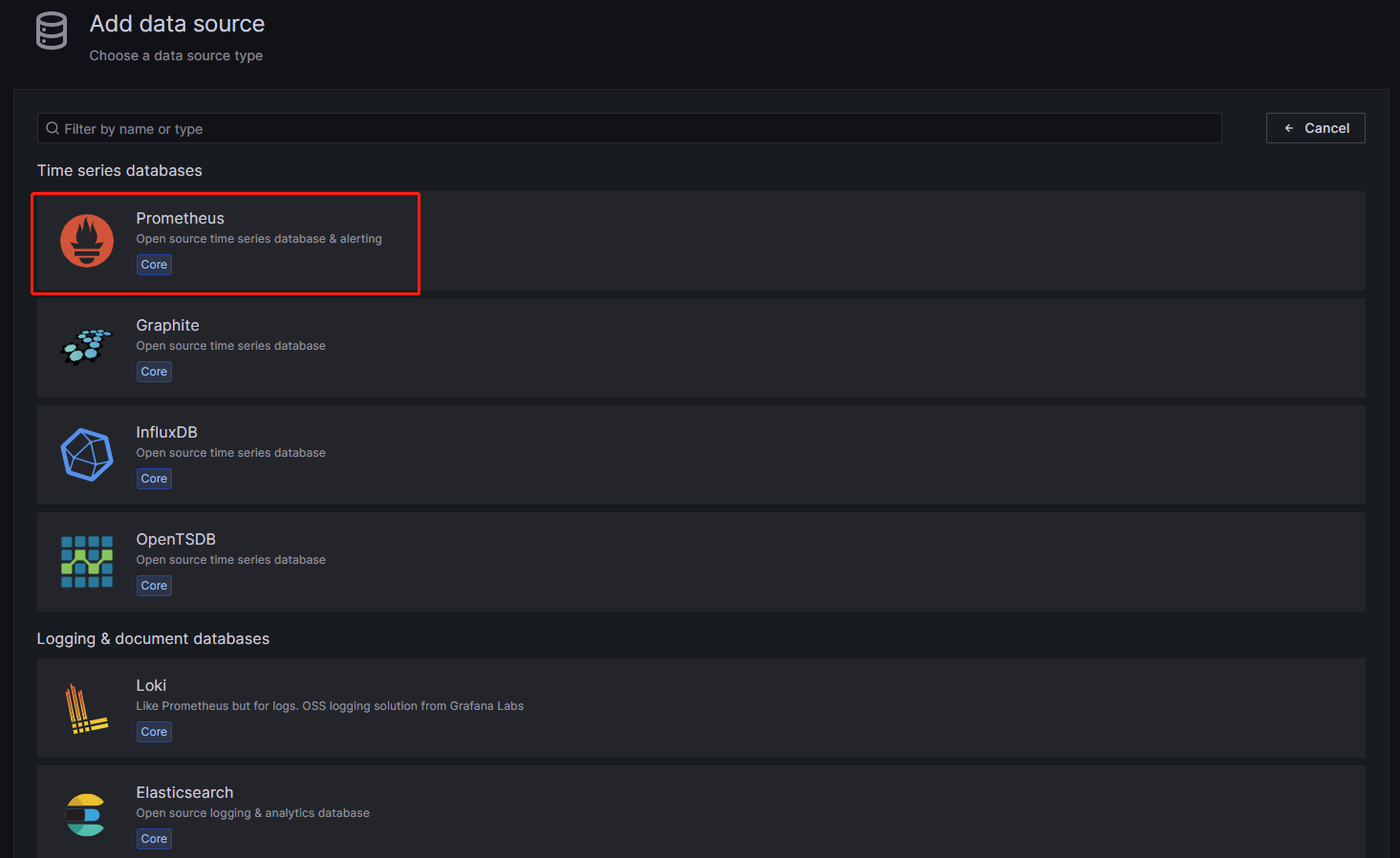
选择Prometheus数据源:
添加Prometheus的地址:
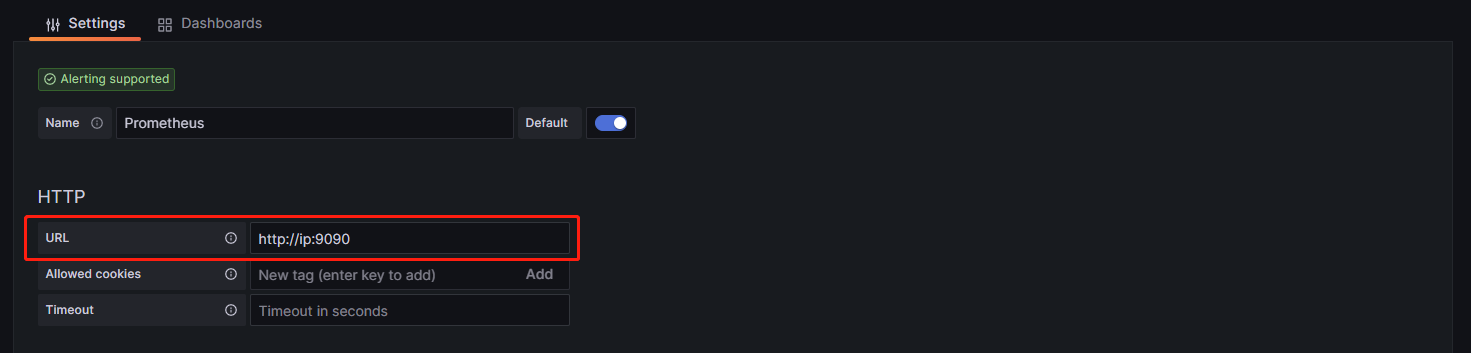
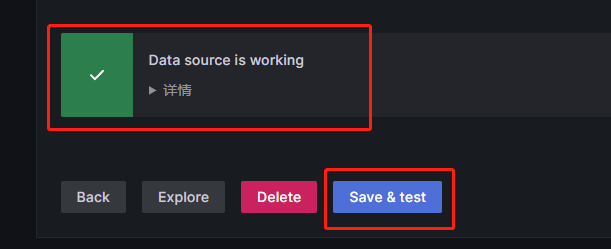
然后点击保存并测试,如果测试成功了就说明数据源配置完成了:
添加仪表盘
有关于如何展示操作系统和硬件相关的指标数据,Grafana社区中有很多现成的仪表盘模板,可以直接引用。
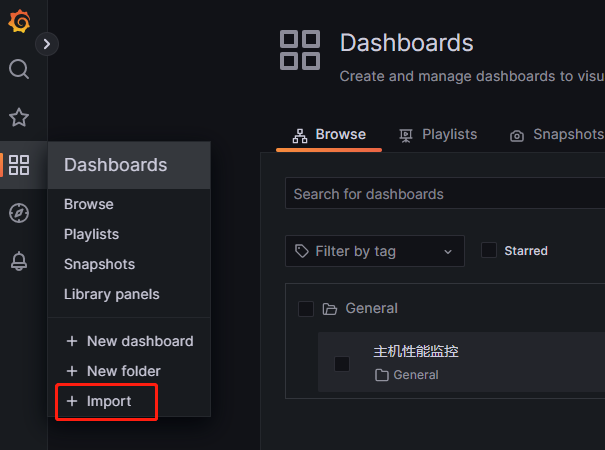
选择引入仪表盘:
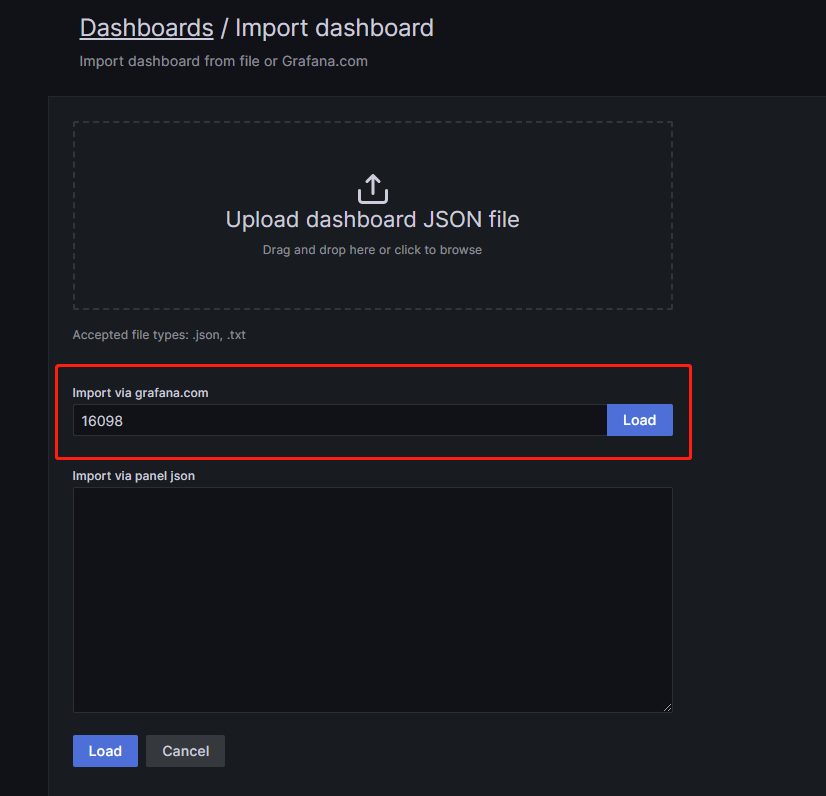
输入一串数字,这是Grafana社区中一个比较流行的模板的编号,然后点击右边的Load:
修改一下仪表盘名称,并选择刚刚配置的Prometheus数据源,然后点击import:
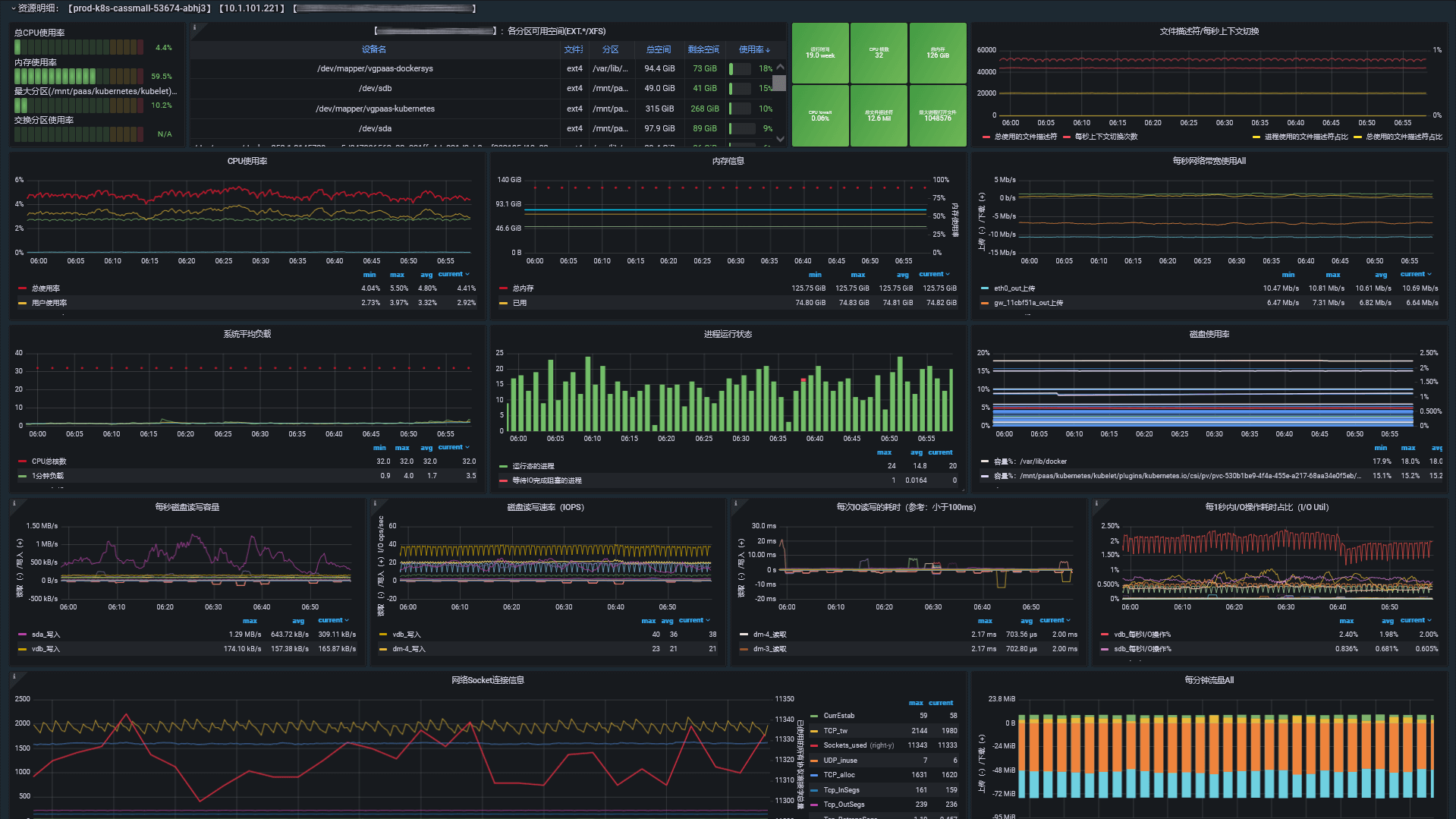
这样就能看到主机性能的各项指标了:
 微信
微信 支付宝
支付宝